
"Analiza danych w biznesie. Sztuka podejmowania skutecznych decyzji"

Foster PROVOST

Tom FAWCETT
.Jednymi z najważniejszych podstawowych pojęć nauki o danych są pojęcia nadmiernego dopasowania i generalizacji. Jeśli pozwolimy sobie na wystarczającą elastyczność podczas poszukiwania wzorców w konkretnym zbiorze danych, to te wzorce znajdziemy. Niestety, te „wzorce” mogą być tylko zdarzeniami losowymi w ramach danych. Jesteśmy zainteresowani wzorcami, które dokonują generalizacji — prawidłowo prognozują wystąpienia, których jeszcze nie zaobserwowaliśmy. Znajdowanie w danych zdarzeń losowych, które wyglądają jak interesujące wzorce, ale które nie generalizują, nazywa się nadmiernym dopasowaniem danych.
Generalizacja
.Rozważmy następujący (skrajny) przykład. Jesteś kierownikiem w MegaTelCo, odpowiedzialnym za zmniejszenie odpływu klientów. Ja prowadzę grupę doradczą ds. eksploracji danych. Przekazujesz mojemu zespołowi badaczy danych zbiór danych historycznych dotyczących klientów, którzy nadal korzystają z usług firmy, oraz klientów, którzy odeszli w ciągu sześciu miesięcy po wygaśnięciu umowy. Moim zadaniem jest zbudowanie modelu określającego, którzy klienci prawdopodobnie zrezygnują z usług firmy, na podstawie określonych cech. Ja przeprowadzam eksplorację danych i buduję model. Przekazuję Ci kod modelu w celu zaimplementowania go w systemie redukcji odpływu klientów Twojej firmy.
Ciebie interesuje oczywiście to, czy mój model nadaje się do czegokolwiek, więc prosisz swój zespół techniczny, aby sprawdził skuteczność modelu na danych historycznych. Oczywiście, skuteczność historyczna nie jest gwarancją przyszłego sukcesu, ale z doświadczenia wiesz, że wzorce rezygnacji pozostają względnie stabilne, o ile nie wiążą się z dużymi zmianami w branży (takimi jak np. pojawienie się iPhone’a), a wiesz, że od czasu zebrania danych takich poważnych zmian nie było. Zespół techniczny przepuszcza więc zbiór danych historycznych przez model. Jego szef informuje Cię, że ten zespół ds. nauki o danych jest niesamowity. Model jest w 100% dokładny. Nie popełnia ani jednego błędu i prawidłowo identyfikuje zarówno wszystkich rezygnujących, jak i wszystkich pozostających w firmie klientów.
Masz wystarczające doświadczenie, aby nie czuć się komfortowo z tym stwierdzeniem. Twoi eksperci długo śledzili zachowania związane z rezygnacjami i gdyby wskaźniki naprawdę były w 100% dokładne, to zdajesz sobie sprawę, że sytuacja wyglądałaby lepiej niż obecnie. Być może to po prostu szczęśliwy traf?
To nie był szczęśliwy traf. Nasz zespół nauki o danych może przygotowywać takie rozwiązania raz za razem. Oto, w jaki sposób zbudowaliśmy model. Umieściliśmy wektor cech dla każdego klienta, który zrezygnował, w tabeli bazy danych. Nazwijmy ją Tc. Następnie, w fazie wykorzystania, gdy do modelu wprowadzane są dane klienta w celu określenia prawdopodobieństwa jego rezygnacji, model podstawia wektor cech klienta, sprawdza w Tc i raportuje „100% prawdopodobieństwa rezygnacji”, jeśli klient znajduje się w Tc, i „0 % prawdopodobieństwa rezygnacji”, jeśli klient nie znajduje się w Tc. Gdy więc zespół techniczny zastosuje nasz model do zbioru danych historycznych, będzie on prognozował doskonale[1].
To proste podejście nazywamy modelem tabelowym. Zapamiętuje on dane i nie dokonuje żadnej generalizacji. Co jest w nim problemem? Zastanówmy się, jak będziemy wykorzystywać ten model w praktyce. Kiedy będzie zbliżał się termin wygaśnięcia umowy wcześniej nieznanego klienta, my będziemy chcieli zastosować model. Klient nie znalazł się oczywiście w zbiorze danych historycznych, więc wyszukiwanie się nie powiedzie, bo brak będzie dokładnego dopasowania, i model przewidzi „0% prawdopodobieństwa rezygnacji” dla tego klienta. Faktycznie model będzie prognozował taką sytuację dla każdego klienta nieznajdującego się w danych uczących. Model, który wyglądał doskonale, będzie zupełnie bezużyteczny w praktyce!
.Ten scenariusz może wydawać się absurdalny. W warunkach rzeczywistych nikt nie wrzuca nieprzetworzonych danych klientów do tabeli i nie stwierdza, że to „model predykcyjny” czegokolwiek. Istotne jest jednak zastanowienie się, dlaczego jest to zły pomysł, ponieważ zawodzi on z tego samego powodu, z jakiego mogą zawieść inne, bardziej realistyczne działania z zakresu eksploracji danych. To skrajny przykład dwóch powiązanych ze sobą podstawowych pojęć nauki o danych: generalizacji i nadmiernego dopasowania. Generalizacja jest własnością modelu lub procesu modelowania polegającą na tym, że model zostaje zastosowany do danych, które nie zostały wykorzystane do jego budowy. W naszym przykładzie model nie dokonuje w ogóle generalizacji poza danymi, które zostały użyte do jego budowy. Jest dostosowany do tego, aby doskonale „pasował” do danych uczących. W warunkach rzeczywistych jest to „nadmierne dopasowanie”.
.To istotna kwestia. Każdy zbiór danych to skończona próbka populacji — w tym przypadku populacji klientów firmy telekomunikacyjnej. Zależy nam na modelach, które moglibyśmy zastosować nie tylko do zbioru uczącego, ale do całej populacji, z której pochodzą dane uczące. Moglibyśmy się martwić, że dane nie były reprezentatywne dla całej populacji, ale nie to jest w tym miejscu problemem. Dane były reprezentatywne, ale eksploracja danych nie stworzyła modelu, który dokonywałby generalizacji wykraczającej poza dane.
Nadmierne dopasowanie („przeuczenie”)
.Nadmierne dopasowanie to tendencja procedur eksploracji danych do dostosowywania modelu do danych kosztem generalizacji nieznanych wcześniej punktów danych. Przykład powyższy został zaaranżowany; eksploracja danych zbudowała model, wykorzystując wyłącznie zapamiętywanie, najbardziej skrajną procedurę nadmiernego dopasowania, jaka jest możliwa. Wszystkie procedury eksploracji danych mają jednak do pewnego stopnia tendencję do nadmiernego dopasowywania — jedne mniejszą, inne większą. Chodzi o to, że jeśli przyglądamy się wyjątkowo uważnie, to znajdziemy w zbiorze danych wzorce. Jak stwierdził laureat Nagrody Nobla Ronald Coase: „Jeśli odpowiednio długo będziemy torturowali dane, to one w końcu się przyznają”.
Niestety, problem jest podstępny. Jego rozwiązanie nie polega na zastosowaniu procedury eksploracji danych, która nie będzie podatna na nadmierne dopasowanie, bo podatne są wszystkie. Nie jest także rozwiązaniem stosowanie modeli, w przypadku których poziom nadmiernego dopasowania jest najmniejszy, ponieważ istnieje zasadniczy kompromis między złożonością modelu a możliwością „przeuczenia”. Czasami może nam po prostu zależeć na bardziej złożonych modelach, ponieważ będą one w stanie lepiej uchwycić rzeczywistą złożoność sytuacji modelowanej, a tym samym będą bardziej precyzyjne. Nie istnieje jedynie słuszny wybór czy procedura, która eliminuje nadmierne dopasowanie. Najlepszą strategią jest rozpoznawać nadmierne dopasowania i zarządzać złożonością w uporządkowany sposób.
Bardziej szczegółowo omówimy nadmierne dopasowanie, metody oceny stopnia nadmiernego dopasowania w czasie modelowania oraz metody unikania nadmiernego dopasowania, na ile to możliwe.
Badanie nadmiernego dopasowania
.Zanim zastanowimy się, jak radzić sobie z nadmiernym dopasowaniem, musimy wiedzieć, jak je rozpoznać. Przedstawimy proste narzędzie analityczne: wykres dopasowania. Wykres dopasowania ukazuje dokładność modelu w funkcji jego złożoności. Do badania nadmiernego dopasowania musimy wprowadzić pojęcie, które ma zasadnicze znaczenie dla ewaluacji w ramach nauki o danych: dane wydzielone.
Problem z przykładem powyżej polegał na tym, że model był ewaluowany na dokładnie tych samych danych, które zostały wykorzystane do jego budowy. Ewaluacja na danych uniemożliwia ocenę tego, na ile prawidłowo model dokonuje generalizacji w przypadkach nieznanych. Niezbędne jest więc „wydzielenie” pewnych danych, dla których znamy wartość zmiennej docelowej, ale które nie będą wykorzystane do budowy modelu. Nie są to rzeczywiste dane robocze, dla których ostatecznie chcielibyśmy przewidzieć wartość zmiennej docelowej. Tworzenie danych wydzielonych przypomina raczej tworzenie „testu laboratoryjnego” skuteczności generalizacji. Na tych danych wydzielonych będziemy symulować scenariusz użycia: ukryjemy w nich przed modelem (i być może przed osobami modelującymi) rzeczywiste wartości wielkości docelowej. Model będzie przewidywał te wartości. Następnie oszacujemy skuteczność generalizacji poprzez porównanie przewidywanych wartości z ukrytymi wartościami rzeczywistymi. Prawdopodobnie wystąpi różnica między dokładnością w zbiorze danych uczących model (nazywaną czasem dokładnością „w próbce”) i dokładnością generalizacji modelu, szacowaną na podstawie danych wydzielonych. Gdy dane wydzielone są wykorzystywane w ten sposób, często nazywa się je „zbiorem testowym”.
.Dokładność modelu zależy od tego, na jaki stopień złożoności mu zezwolimy. Model może być złożony na różne sposoby. Najpierw jednak wykorzystamy rozróżnienie pomiędzy danymi wejściowymi i danymi wydzielonymi, aby bardziej precyzyjnie zdefiniować krzywą dopasowania. Wykres dopasowania (patrz rysunek 5.1) ukazuje różnicę między dokładnością procedury modelowania na danych uczących i dokładnością na danych wydzielonych, wraz ze zmianami stopnia złożoności modelu. Ogólnie rzecz biorąc, poziom nadmiernego dopasowania będzie większy, jeśli zezwolimy modelowi na większą złożoność. (W kontekście technicznym prawdopodobieństwo „przeuczenia” wzrasta, gdy pozwalamy procedurze modelującej na większą elastyczność modeli, które może ona wytworzyć).
Rysunek 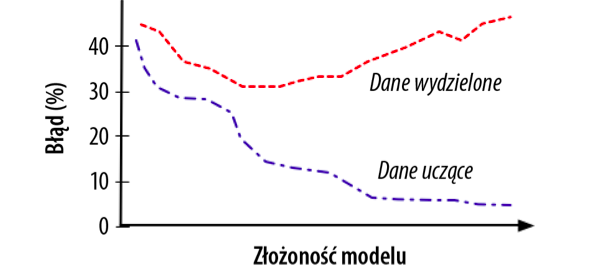 5.1. Typowy wykres dopasowania. Każdy punkt na krzywej oznacza oszacowanie dokładności modelu o określonej złożoności (jak zaznaczono na osi poziomej). Szacunki dokładności na danych uczących i danych testowych zmieniają się w różny sposób, w zależności od tego, na jaki stopień złożoności zezwolimy modelowi. Gdy nie pozwolimy, aby model był odpowiednio złożony, nie będzie on także szczególnie dokładny. Kiedy modele stają się nadmiernie złożone, to wyglądają na bardzo dokładne na danych uczących, ale faktycznie dochodzi do nadmiernego dopasowania — dokładność na podstawie danych uczących odbiega od dokładności na danych wydzielonych (dokładności generalizacji)
5.1. Typowy wykres dopasowania. Każdy punkt na krzywej oznacza oszacowanie dokładności modelu o określonej złożoności (jak zaznaczono na osi poziomej). Szacunki dokładności na danych uczących i danych testowych zmieniają się w różny sposób, w zależności od tego, na jaki stopień złożoności zezwolimy modelowi. Gdy nie pozwolimy, aby model był odpowiednio złożony, nie będzie on także szczególnie dokładny. Kiedy modele stają się nadmiernie złożone, to wyglądają na bardzo dokładne na danych uczących, ale faktycznie dochodzi do nadmiernego dopasowania — dokładność na podstawie danych uczących odbiega od dokładności na danych wydzielonych (dokładności generalizacji)

Rysunek 5.2 przedstawia wykres dopasowania dla „modelu tabelowego” odpływu abonentów, opisanego wcześniej. Ponieważ był to przykład skrajny, krzywe dopasowania będą osobliwe. Także w tym przypadku oś x określa złożoność modelu, tutaj liczbę wierszy w tabeli. Oś y zawiera pomiar błędu. Umożliwiając tabeli rozrastanie się, możemy zapamiętywać coraz więcej elementów zbioru uczącego, a z każdym nowym wierszem błąd zbioru uczącego się zmniejsza. W końcu tabela stanie się na tyle duża, że pomieści cały zbiór uczący (oznaczony jako N na osi x), a błąd osiągnie wartość zero i taki pozostanie. Błąd zbioru testowego (wydzielonego) pojawia się przy pewnej wartości (nazwijmy ją b) i nigdy się nie zmniejsza, bo zbiory uczący i wydzielony nigdy nie zachodzą na siebie. Duża luka pomiędzy nimi wyraźnie wskazuje na zapamiętywanie.
Czym jest b? Skoro model tabelowy zawsze przewiduje brak rezygnacji dla każdego nowego przypadku, który zostanie mu przedstawiony, to uzna każdy przypadek określony jako brak rezygnacji za prawidłowy, a każdy przypadek rezygnacja za nieprawidłowy. W ten sposób stopą błędu będzie odsetek przypadków rezygnacji w ramach populacji. Ta wartość znana jest jako stopa bazowa, a klasyfikator, który zawsze wybiera klasę większościową, nazywany jest klasyfikatorem stopy bazowej.
Analogicznie, podstawą modelu regresji jest prosty model, który zawsze przewiduje średnią lub medianę wartości zmiennej docelowej. Czasami można usłyszeć określenie „skuteczność stopy bazowej” i do tego właśnie się ono odnosi.
Nadmierne dopasowanie w indukcji drzew decyzyjnych
.Przypomnijmy sobie, jak budujemy modele o strukturze drzewa do celów klasyfikacji. Wykorzystujemy podstawową umiejętność znajdowania istotnych, predyktywnych indywidualnych atrybutów (rekurencyjnie) do coraz mniejszych podzbiorów danych. Dla ilustracji załóżmy, że w zbiorze danych nie ma dwóch wystąpień o dokładnie takim samym wektorze cech, ale różnych wartościach wielkości docelowej. Jeżeli w dalszym ciągu będziemy dzielić dane, to w końcu podzbiory staną się czyste — wszystkie wystąpienia będą miały taką samą wartość zmiennej docelowej. Będą to liście naszego drzewa. Liść będzie mógł zawierać wiele wystąpień, z zawsze taką samą wartością zmiennej docelowej. Gdyby było to konieczne, to moglibyśmy nadal dzielić na podstawie atrybutów i segmentować nasze dane, aż każdy węzeł liść zawierałby tylko jedno wystąpienie, które jest czyste z definicji.
.Co właśnie zrobiliśmy? Zasadniczo zbudowaliśmy pewną wersję tabeli wyszukiwania, przedstawionej w poprzednim podrozdziale jako skrajny przykład „przeuczenia”! Każde wystąpienie uczące, umieszczone na drzewie w celu sklasyfikowania, odbędzie podróż w dół, lądując ostatecznie w odpowiednim liściu — odpowiadającym podzbiorowi danych, który zawiera to konkretne wystąpienie uczące. Jaka będzie dokładność tego drzewa na zbiorze uczącym? Będzie ono idealnie dokładne, prawidłowo prognozując klasę dla każdego wystąpienia uczącego.
Czy będzie generalizować? Być może. To drzewo powinno być nieco lepsze niż tabela wyszukiwania, bo każde wcześniej nieznane wystąpienie zostanie jakoś sklasyfikowane, a nie po prostu określone jako niepasujące; drzewo dokonuje nietrywialnej klasyfikacji nawet dla przypadków, których wcześniej nie znało. Dlatego dobrze jest doświadczalnie zbadać, na ile dokładność na zbiorze uczącym odpowiada dokładności na danych testowych.
.Procedura tworzenia drzew rozrastających się do czasu, aż liście będą czyste, wykazuje tendencję do nadmiernego dopasowania. Modele o strukturze drzewa są bardzo elastyczne w kwestii tego, co mogą przedstawiać. Mogą one faktycznie prezentować jakąkolwiek funkcję cech, a jeżeli umożliwimy im rozrastanie się bez ograniczeń, to będą w stanie dopasować ją z dowolną precyzją. Żeby jednak tak się stało, drzewa będą prawdopodobnie musiały być ogromne. Stopień złożoności drzew określa liczba ich węzłów.
Rysunek 5.3 przedstawia typowe krzywe dopasowania dla indukcji drzew decyzyjnych. Tutaj sztucznie ograniczyliśmy maksymalny rozmiar każdego drzewa, mierzony dozwoloną liczbą węzłów, wskazany na osi x (która jest dla wygody skalą logarytmiczną). Dla każdego rozmiaru drzewa tworzymy od podstaw nowe drzewo przy użyciu danych uczących. Mierzymy dwie wartości: jego dokładność na zbiorze uczącym i dokładność na zbiorze wydzielonym (testowym). Jeśli podzbiory danych w liściach nie będą czyste, to będziemy prognozować wartość zmiennej docelowej na podstawie jakiejś średniej z wartości wielkości docelowej w danym podzbiorze.

Rysunek 5.3. Typowy wykres dopasowania dla indukcji drzew decyzyjnych
.Zaczynamy od lewej strony. Drzewo jest tutaj bardzo małe i ma małą skuteczność. Gdy zezwalamy mu na coraz więcej węzłów, jego skuteczność poprawia się w szybkim tempie, a dokładność zarówno na zbiorze uczącym, jak i wydzielonym poprawia się także. Widzimy również, że dokładność zbioru uczącego jest zawsze przynajmniej nieco lepsza niż dokładność zbioru wydzielonego, bo spoglądaliśmy w dane uczące podczas budowania modelu. W pewnym momencie jednak drzewo zaczyna wykazywać nadmierne dopasowanie: pozyskuje szczegóły zbioru uczącego, które nie charakteryzują populacji jako całości, co widać w zbiorze wydzielonym. Zaczyna się to około wartości x = 100 węzłów, oznaczonej jako „czuły punkt” na wykresie. Kiedy pozwalamy drzewom rosnąć, dokładność na zbiorze uczącym nadal wzrasta — i model będzie w stanie faktycznie zapamiętać cały zbiór uczący, jeżeli mu na to pozwolimy, co prowadzi do dokładności 1,0 (nie widać tego na wykresie). Dokładność na zbiorze wydzielonym spada jednak, kiedy rozrost drzewa wykracza poza „czuły punkt”; podzbiory danych w liściach stają się coraz mniejsze, a model dokonuje generalizacji na podstawie coraz mniejszej ilości danych. Takie wnioskowanie jest coraz bardziej podatne na błędy i skuteczność na danych wydzielonych będzie coraz mniejsza.
Podsumowując, z tego wykresu dopasowania możemy wywnioskować, że nadmierne dopasowanie na tym zbiorze danych pojawia się przy wartości około 100 węzłów, a więc powinniśmy ograniczyć rozmiar drzewa do tej wartości[2]. To najlepszy kompromis między skrajnościami, którymi są (i) rezygnacja z dzielenia danych i wykorzystywanie po prostu średniej wartości wielkości docelowej w całym zbiorze danych, oraz (ii) tworzenie kompletnego drzewa, aż liście będą czyste.
Niestety, nikt nie opracował jeszcze teoretycznej procedury dokładnego oznaczania czułego punktu, więc musimy polegać na technikach heurystycznych. Zanim je jednak omówimy, zbadajmy nadmierne dopasowanie w drugim rodzaju procedury modelowania.
Nadmierne dopasowanie w funkcjach matematycznych
Istnieją różne sposoby umożliwiające doprowadzenie do większej lub mniejszej złożoności funkcji matematycznych. Problemowi temu poświęcono cały szereg książek. W tym miejscu dokonamy skrótu i podamy tylko informacje niezbędne do zrozumienia tego rodzaju dyskusji na poziomie koncepcyjnym[3]. Najpierw jednak przedyskutujmy o wiele prostszy sposób, za sprawą którego funkcje mogą stać się nadmiernie złożone.
Jednym ze sposobów zwiększania złożoności funkcji matematycznych jest zwiększanie liczby zmiennych (atrybutów). Powiedzmy na przykład, że dysponujemy modelem liniowym, opisanym w równaniu 4.2:
f(x) = w0 + w1x1 + w2x2 + w3x3
Gdy będziemy dodawać kolejne xi, stopień złożoności funkcji zacznie się zwiększać. Każda wartość xi posiada odpowiadającą jej wartość wi, która jest nauczonym parametrem modelu.
Twórcy modeli czasem nawet przekształcają typowo liniowe funkcje, dodając nowe atrybuty, które są nieliniowymi wersjami innych atrybutów. Moglibyśmy na przykład dodać czwarty atrybut x4 = x12. Moglibyśmy też uznać, że istotny jest stosunek x2 do x3, dodalibyśmy więc nowy atrybut x5 = x2/x3. Teraz spróbujemy znaleźć parametry (wagi) równania:
f(x) = w0 + w1x1 + w2x2 + w3x3 + w4x4 + w5x5
Tak czy inaczej, zbiór danych może zyskać bardzo dużą liczbę atrybutów, a wykorzystanie ich wszystkich daje procedurze modelowania dużą swobodę dopasowywania się do zbioru uczącego. Być może pamiętasz z geometrii, że w dwóch wymiarach można przeprowadzić linię przez dowolne dwa punkty, a w trzech wymiarach można dopasować do dowolnych trzech punktów płaszczyznę. To pojęcie generalizujące: zwiększając liczbę wymiarów, można idealnie dopasować coraz większe zbiory dowolnych punktów. A nawet jeśli nie możemy dopasować danych doskonale, to można dopasowywać je coraz lepiej, dysponując większą liczbą wymiarów — czyli większą liczbą atrybutów.
.Często  twórcy modeli starannie przycinają atrybuty w celu uniknięcia „przeuczenia”. Stosują oni rodzaj techniki wydzielania, opisanej powyżej, do oceny informacji w ramach poszczególnych atrybutów. Uważna ręczna selekcja atrybutów jest rozsądną praktyką w przypadkach, w których można na modelowanie poświęcić znaczną ilość sił i środków i w których występuje stosunkowo niewiele atrybutów. W wielu nowoczesnych zastosowaniach, w których znaczną liczbę modeli buduje się automatycznie lub w których występują bardzo duże zbiory atrybutów, ręczna selekcja może być niewykonalna. Na przykład firmy zajmujące się opartym na analityce danych targetowaniem reklam internetowych budują co tydzień tysiące modeli, mogących mieć miliony możliwych cech. W takich przypadkach nie ma wyboru i konieczne jest stosowanie automatycznej selekcji cech – lub całkowite jej zignorowanie.
twórcy modeli starannie przycinają atrybuty w celu uniknięcia „przeuczenia”. Stosują oni rodzaj techniki wydzielania, opisanej powyżej, do oceny informacji w ramach poszczególnych atrybutów. Uważna ręczna selekcja atrybutów jest rozsądną praktyką w przypadkach, w których można na modelowanie poświęcić znaczną ilość sił i środków i w których występuje stosunkowo niewiele atrybutów. W wielu nowoczesnych zastosowaniach, w których znaczną liczbę modeli buduje się automatycznie lub w których występują bardzo duże zbiory atrybutów, ręczna selekcja może być niewykonalna. Na przykład firmy zajmujące się opartym na analityce danych targetowaniem reklam internetowych budują co tydzień tysiące modeli, mogących mieć miliony możliwych cech. W takich przypadkach nie ma wyboru i konieczne jest stosowanie automatycznej selekcji cech – lub całkowite jej zignorowanie.
Foster Provost
Tom Fawcett
Fragment książki „Analiza danych w biznesie. Sztuka podejmowania skutecznych decyzji”, wyd.OnePress/Helion POLECAMY [LINK]
[1] Z technicznego punktu widzenia niekoniecznie jest to prawdą: mogą istnieć dwaj klienci z takim samym opisem wektora cech, z których jeden rezygnuje, a drugi nie. W naszym przykładzie tę możliwość ignorujemy. Możemy na przykład założyć, że jedną z cech jest unikalny numer identyfikacyjny klienta.
[2] Pamiętajmy, że 100 węzłów nie jest jakąś szczególną, uniwersalną wartością. Odnosi się do tego konkretnego zbioru danych. Gdybyśmy znacząco zmienili dane albo po prostu zastosowali inny algorytm budowy drzewa, to prawdopodobnie chcielibyśmy stworzyć inny wykres dopasowania, aby znaleźć nowy czuły punkt.
[3] Do tego czasu będziemy także dysponowali wystarczającym zestawem narzędzi koncepcyjnych, aby nieco lepiej zrozumieć maszyny wektorów wspierających — jako prawie równoznaczne z regresją logistyczną z kontrolą złożoności (przeuczenia).











